This tutorial will walk through building a demo which uses Elasticsearch to do word-by-word completion. The demo is a single-dependency Go app with a minimal UI. If you mostly care about the Elasticsearch usage, see the "overview" and "backend - next word search" sections. The final code is available at this Github repo
This is a pretty detailed tutorial, probably oriented towards Elasticsearch and Go beginners, with full working code blocks. It's also my first tutorial-like blog post -- if you have any feedback, feel free to open an issue on the repo!
What is "autocomplete word-by-word"?
Normal autocomplete (i.e. Google search) usually completes the full phrase like this, which may have results with the same first few words:
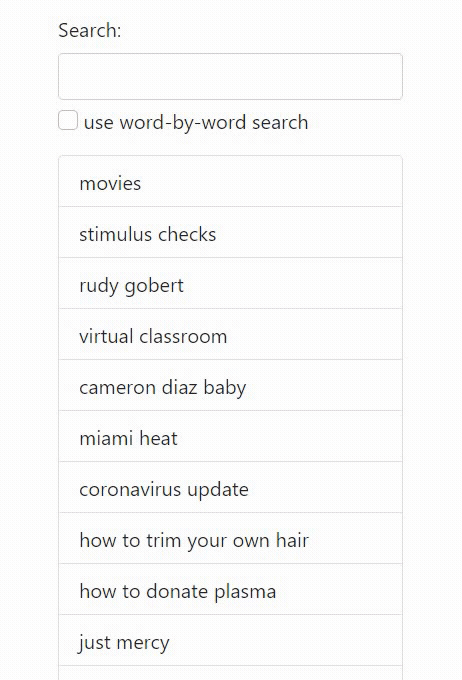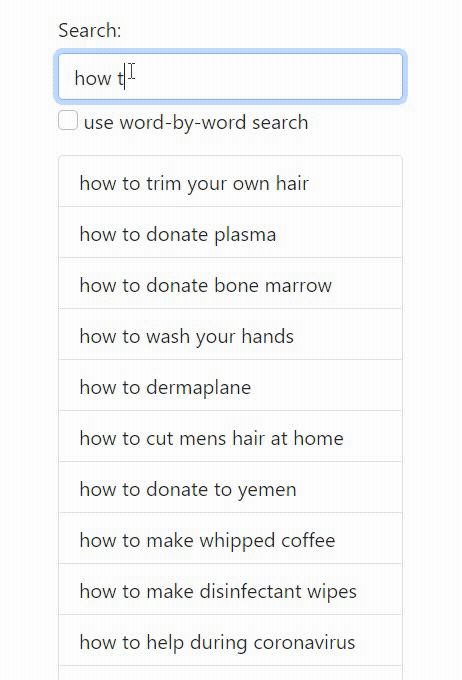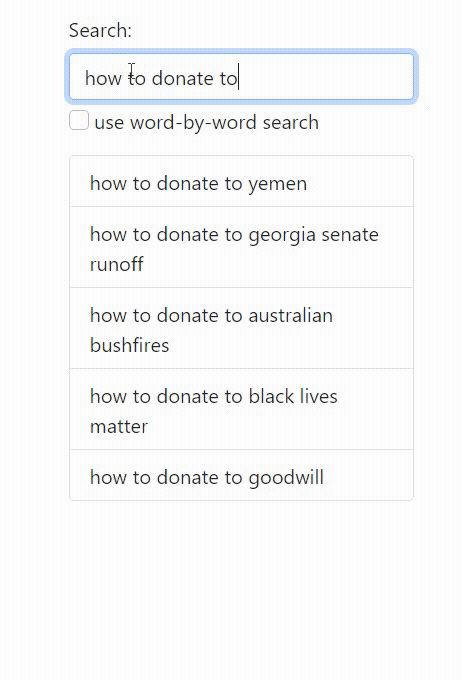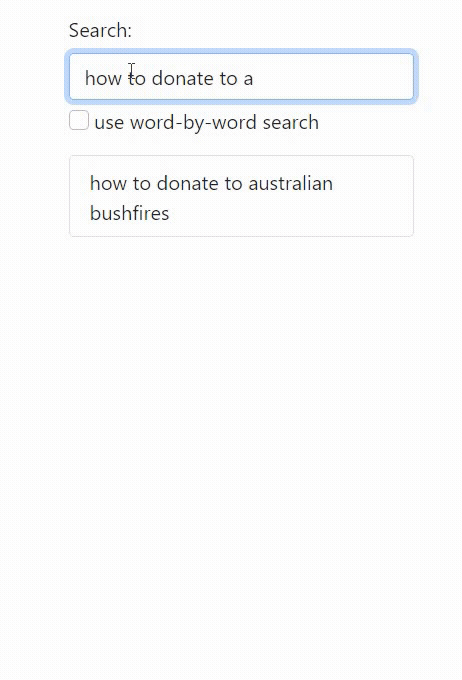
While word-by-word autocomplete (i.e. smartphone keyboards) trades off having to click/type more, but deduplicates common words in the beginning:
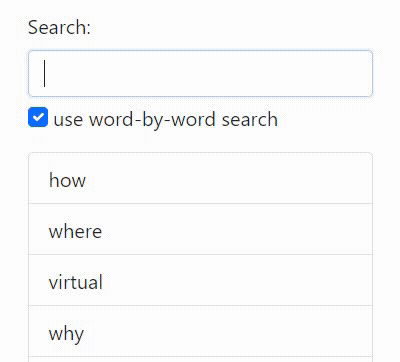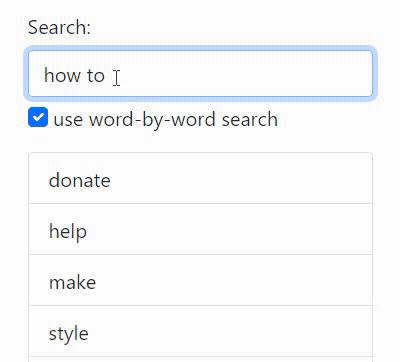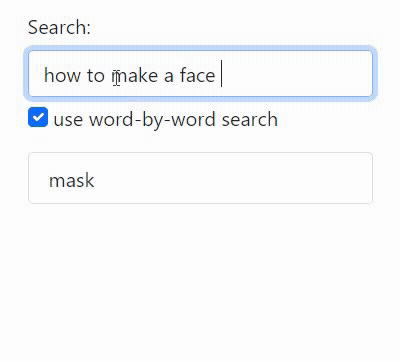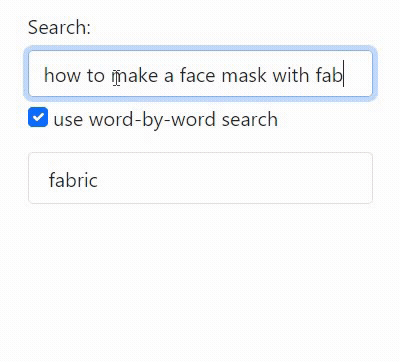
App overview
The demo will use three components:
- Elasticsearch will run in the background, filled with Google's "Year In Search 2020" entries
- A UI where search results will update as the user types
- We'll do this with just one
index.htmlfile thanks to the Vue and Bootstrap frameworks.
- We'll do this with just one
- A REST API that sends requests to Elasticsearch and returns them to the UI
- We'll use Go as it is a nice combination of being a compiled lang + concise syntax + has all the built-in libraries we need
- We'll use
olivere/elasticas our only dependency to make Elasticsearch API calls easier.
Elasticsearch usage
Each ES document will be the full search phrase, eg. how to donate plasma. We expect the user input to be a prefix search.
We can think of this as a filter + map + reduce pure function:
Described visually:
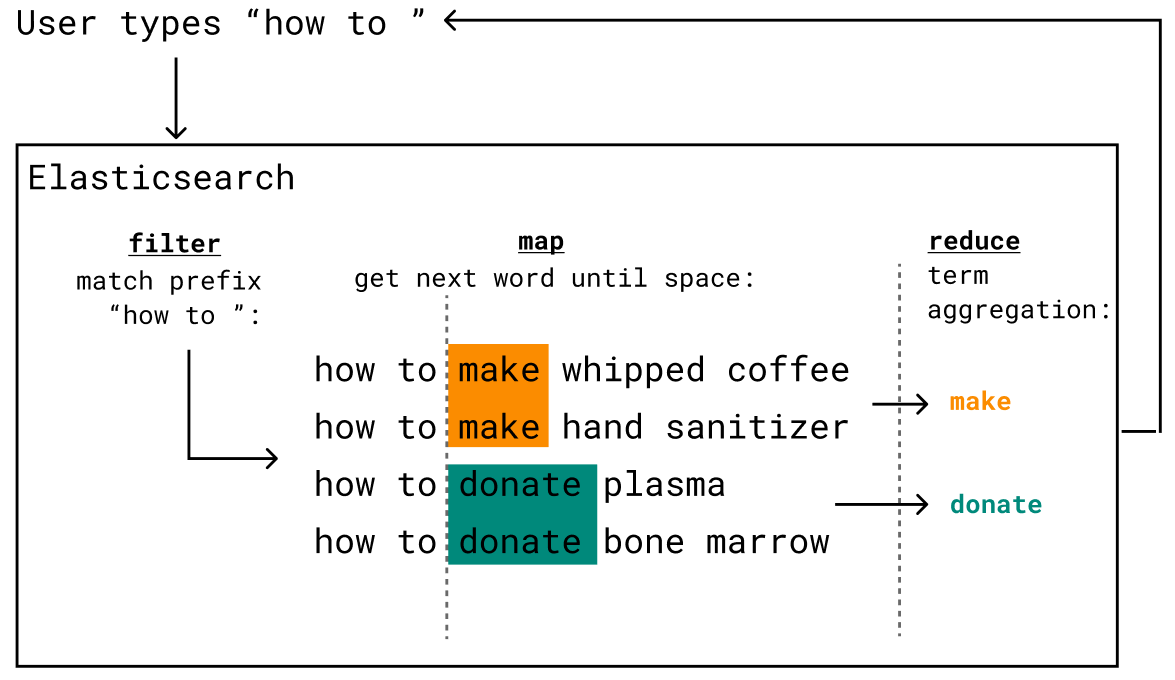
Described in text:
- Filter in documents matching the prefix - We'll use Elasticsearch prefix queries and the
keywordfield type - Map the search phrase field to the substring between the start of the current word, and the next occurrence of a space character - We'll use ES stored scripts and their Painless language.
- Reduce a.k.a. dedeuplicate the substrings - We'll use an Elasticsearch Term Aggregation
With those ideas in mind, let's jump into the code!
Populating Elasticsearch
This is an easy way I've found to get Elasticsearch running ASAP for personal projects:
- Download an archive from their site
- Run
bin/elasticsearchand wait forlocalhost:9200to respond
With Elasticsearch up and running, let's write some Go code to populate it. Start by setting up a Go project:
mkdir es-next-words
cd es-next-words
go mod init <your module name>
# our only dependency
go get github.com/olivere/elastic/v7
We're going to write the go program be used like this:
go run main.go # starts the server
go run main.go populate data.txt # populates elasticsearch
For a bit of organization, let's create a folder structure like this:
main.go
lib/
common.go
server.go
setup.go
And start with a main function like this:
func main() {
args := os.Args[1:]
if len(args) == 0 || args[0] == "serve" {
fmt.Println("got no args, running server")
} else if args[0] == "populate" {
lib.PopulateIndex()
}
}
I've created a textfile here listing most of Google's "Year in Search 2020" search phrases.
Feel free to download it and put it in a data/ folder!
Let's set up some constants and a struct representing our ES documents:
package lib
const INDEX = "searches"
type SearchDoc struct {
Search string `json:"search"`
}
// helper to stop the app on any startup errors
func Check(e error) {
if e != nil {
panic(e)
}
}
And fill in our populator helper method. Let's have it check for the index and delete it so that the program is idempotent:
func PopulateIndex() {
client, err := elastic.NewClient()
Check(err)
exists, err := client.IndexExists(INDEX).Do(context.Background())
Check(err)
if exists {
fmt.Println("index exists")
deleteIndex, err := client.DeleteIndex(INDEX).Do(context.Background())
Check(err)
fmt.Printf("delete acknowledgement: %v\n", deleteIndex.Acknowledged)
}
}
Then, the code should create the index. String fields in ES default to the field type "text",
but since we'll be doing Prefix queries and Term aggregations on search phrases,
we want the field to be of type keyword:
resp, err := client.CreateIndex(INDEX).BodyString(`{"mappings" : {
"properties" : {
"search" : { "type" : "keyword" }
}}}`).Do(context.Background())
Check(err)
fmt.Printf("create index: %v\n", resp.Acknowledged)
Then we can read through the .txt file and bulk-index all the entries like so:
data, err := os.ReadFile("./data/data.txt")
Check(err)
searches := strings.Split(string(data), "\n")
bulkRequest := client.Bulk()
for id, search := range searches {
bulkRequest.Add(elastic.NewBulkIndexRequest().
Index(INDEX).
Id(strconv.Itoa(id)).
Doc(SearchDoc{search}))
}
bulkResponse, err := bulkRequest.Do(context.Background())
Check(err)
indexed := bulkResponse.Indexed()
fmt.Printf("parsed %d searches, indexed %d searches\n",
len(searches),
len(indexed))
} // end PopulateIndex()
After that, as long as your Elasticsearch is running at localhost:9200,
running this should populate the searches index:
$ go run main.go populate
# Verify:
$ curl localhost:9200/searches/_count
{"count":296,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0}}
The backend - normal prefix search
Let's first get an HTTP API working. Add this line to main:
fmt.Println("got no args, running server")
lib.NewServer().Start()
And add this boilerplate HTTP server code to server.go:
type Server struct {
client *elastic.Client
}
func NewServer() *Server {
client, err := elastic.NewClient()
Check(err)
return &Server{
client: client,
}
}
func (s *Server) Start() {
http.HandleFunc("/search", s.searchHandler)
log.Panic(http.ListenAndServe(":8000", nil))
}
Our REST API will take in a JSON body. I would have liked to use
HTTP query params, but it seems trailing spaces on param values get trimmed, which won't
work for this demo. We need to distinguish between the user typing "how" -- which means to look for words beginning with those three characters --
versus "how ", which should look for full words following the word "how".
I'm also going to keep error handling very lazy going forward; any fancier error handling is up to the reader 😊.
type PrefixBody struct {
Prefix string `json:"prefix"`
UseNextWord bool `json:"useNextWord"`
}
func (s *Server) searchHandler(w http.ResponseWriter, r *http.Request) {
decoder := json.NewDecoder(r.Body)
var prefixBody PrefixBody
err := decoder.Decode(&prefixBody)
if err != nil {
fmt.Println()
fmt.Fprintf(w, "%v", err)
return
}
hits := s.doNextWordSearch(prefixBody.Prefix)
json.NewEncoder(w).Encode(hits)
}
And let's fill in the helper method to just run a prefix query for now.
olivere/elastic handles most the logic for us:
func (s *Server) doNextWordSearch(prefix string) []string {
q := elastic.NewPrefixQuery("search", prefix)
search := s.client.Search().Index(INDEX).Query(q).Pretty(true)
// default return limit (Size) is small, use a larger one
result, err := search.Size(1000).Do(context.Background())
if err != nil {
fmt.Println(err)
return []string{}
}
hits := []string{}
for _, hit := range result.Hits.Hits {
var doc SearchDoc
err := json.Unmarshal(hit.Source, &doc)
if err != nil {
fmt.Println(err)
return []string{}
}
hits = append(hits, doc.Search)
}
return hits
}
After that, you should be able to call the API:
$ go run main.go
# in another terminal
$ curl localhost:8000/search -d '{"prefix":"how"}'
["how to trim your own hair","how to donate plasma",...]
Creating the UI
Let's start making the UI so we can enjoy our fine work as we go along.
- Create a
uifolder as a sibling to thelibfolder:
This is a backend tutorial so I haven't put much effort into the frontend (it's the GIFs at the top of this post), but here is a summary of what it does for the curious:
- Imports Vue (for JS functionality) and Bootstrap (for some CSS theming) from CDNs so you don't have to download anything more
- Sets up two-way binding between some inputs and Javscript variables
- Sets up event handling so that you whenever you type in the search box, it sends an API request and updates the UI
<!DOCTYPE html>
<html>
<head>
<title>next word search demo</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.2/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-uWxY/CJNBR+1zjPWmfnSnVxwRheevXITnMqoEIeG1LJrdI0GlVs/9cVSyPYXdcSF" crossorigin="anonymous">
<script src="https://unpkg.com/vue"></script>
</head>
<body>
<div id="app" class="container-sm pt-4" style="max-width: 300px">
<div class="mb-3">
<label for="search" class="form-label">Search:</label><br>
<input v-on:input="handleInput" v-model="prefix" class="form-control mb-1" type="text" id="search" name="search">
<input v-model="useNextWord" class="form-check-input" type="checkbox" value="" id="useNextWord" checked>
<label class="form-check-label" for="useNextWord">
use word-by-word search
</label>
</div>
<ul class="list-group">
<li v-for="result in results" class="list-group-item">
{{ result }}
</li>
</ul>
</div>
<script>
var app = new Vue({
el: '#app',
data: {
results: [],
useNextWord: true,
prefix: '',
},
methods: {
handleInput: async function () {
const resp = await fetch('http://localhost:8000/search',{
method: 'POST',
body: JSON.stringify({
prefix: this.prefix,
useNextWord: this.useNextWord})
});
this.results = await resp.json();
}
}
})
</script>
</body>
</html>
Add this line to the beginning of Start():
http.Handle("/", http.FileServer(http.Dir("./ui")))
http.HandleFunc("/search", s.searchHandler
And now, if you restart the server, you should be able to use the search box like an autocomplete field
The backend - next word searching
The field mapping script
The ES 6.8 docs have a good example of how to use a map-reduce-like script with term aggregations. I've tested it with ES 7.x and it looks like it's supported.
Let's use the example of a user typing how to d, and a document that looks like how to donate blah.., which should map to donate.
From the user's input, we know which index to start searching for the next space, which I named wordStart below. Our Painless script will look like this:
// Get the search phrase
String val = doc[params.field].value;
// Get where the next space is
int sepIdx = val.indexOf(params.separator, params.wordStart);
// If a space char is found, get the substring up to that point
// If it is NOT found, we have hit the end of the phrase, so return the last word
return sepIdx > 0
? val.substring(params.wordStart, sepIdx)
: val.substring(Integer.min(params.wordStart, val.length()));
I'm having it take in three params for future flexibility, but for our demo, field will always be
"search" and separator will always be " ".
If the user is just typing the first word, we can optimize the script by removing the wordStart param like so.
I'll refer to this script as the first-word script and the previous script as the next-word script.
String val = doc[params.field].value;
int sepIdx = val.indexOf(params.separator);
return sepIdx > 0
? val.substring(0, sepIdx)
: val;
Store script on startup
Let's store the script on server startup to make search times faster. Add:
func (s *Server) Start() {
s.setupScripts()
http.Handle("/", http.FileServer(http.Dir("./ui")))
And let's fill in the helper to call the ES API with our two scripts:
func (s *Server) setupScripts() {
firstWordSource := "String val = doc[params.field].value; int sepIdx = val.indexOf(params.separator); return sepIdx > 0 ? val.substring(0,sepIdx) : val"
nextWordSource := "String val = doc[params.field].value; int sepIdx = val.indexOf(params.separator, params.wordStart); return sepIdx > 0 ? val.substring(params.wordStart, sepIdx): val.substring(Integer.min(params.wordStart, val.length()));"
req := elastic.NewPutScriptService(s.client)
for name, source := range map[string]string{"first-word": firstWordSource, "next-word": nextWordSource} {
body := map[string]map[string]string{
"script": {
"lang": "painless",
"source": source,
},
}
resp, err := req.Id(name).BodyJson(body).Do(context.Background())
Check(err)
fmt.Printf("put script %s: %v\n", name, resp.Acknowledged)
}
}
Integrate script into prefix search
Let's incorporate the use word-by-word search checkbox option from the UI:
func (s *Server) doNextWordSearch(prefix string, useNextWord bool) []string {
...
search := s.client.Search().Index(INDEX).Query(q).Pretty(true)
if useNextWord {
scriptParams := map[string]interface{}{
"field": "search",
"separator": SEPARATOR_STR,
}
} else {
result, err := search.Size(1000).Do(context.Background())
}
We want to use the next-word script if the user has already entered a space char, and the first-word script if not. Focusing on the next-word script usage:
- If the user input does not end in a space eg.
"ho" --> "how", the script'ssubstring()call should start from the left side ofho-. As a tiny optimization, theindexOf()in the script could start from the right side rather than left side ofho, but for simplicitly let's just use the samewordStartparam in bothsubstring()andindexOf(). - If the user input ends in a space, eg.
"how " --> "to",substring()andindexOf()'s search should start from the index after the space.
So we'll determine the wordStart parameter like so:
scriptParams := { ... }
if strings.Contains(prefix, SEPARATOR_STR) {
var wordStart int
if prefix[len(prefix)-1] == SEPARATOR_RUNE {
wordStart = len(prefix)
} else {
wordStart = strings.LastIndex(prefix, SEPARATOR_STR) + 1
}
scriptParams["wordStart"] = wordStart
agg = elastic.NewTermsAggregation().
Script(elastic.NewScriptStored("next-word").
Params(scriptParams))
} else {
agg = elastic.NewTermsAggregation().
Script(elastic.NewScriptStored("first-word").
Params(scriptParams))
}
And after that, we should return the bucket keys from the term aggregation rather than the search hits:
search = search.Size(0).Aggregation("uniques", agg)
result, err := search.Do(context.Background())
if err != nil {
fmt.Println(err)
return []string{}
}
aggResult, found := result.Aggregations.Terms("uniques")
hits := []string{}
if found {
for _, bucket := range aggResult.Buckets {
hits = append(hits, bucket.Key.(string))
}
}
return hits
} else {
// normal prefix search logic
}
After that, you should be able to check the "use word-by-word" option on the UI, and see word-by-word completion happen!
Conclusion
I hope that worked for you and wasn't too verbose! The full source code can be found here
At scale, I've seen a variant of this solution return autocomplete requests on a >1 TB Elasticsearch cluster quickly, with no user-noticeable performance difference when compared to normal queries on the same cluster.
Before I made this tutorial, I also looked around for solutions to the smartphone-autocomplete-like use case but couldn't find a confident answer. However, as further reading, here are some solutions on similar use cases:
- ES Completion suggester - will complete the entire phrase and requires more thought process with the indexing, but probably the closest built-in feature